Kernel Internals
Okay now we know what Docker is but wait, we still don't know the background work which is done to make docker running. Who creates a container in background and who controls it, what makes everything so easy.
When we are working with Docker, actually we are working and talking about containers. Docker is all about containers which you will see after diving below.
Container in IT world is an Isolated area of OS which is bounded to limited resources.
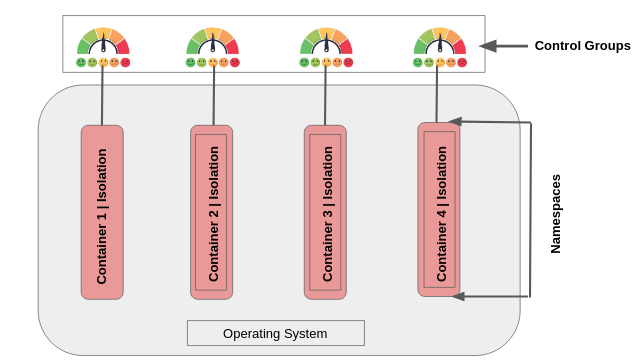
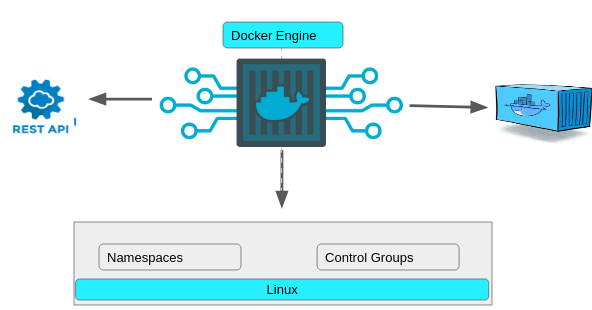
If you see the above image, we have namespaces and control groups, these are just kernel level stuff. you will find more detail below.
Namespaces : A namespace wraps a global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource. Changes to the global resource are visible to other processes that are members of the namespace, but are invisible to other processes. One use of namespaces is to implement containers.
Control Groups: Control groups, usually referred to as cgroups, are a Linux kernel feature which allow processes to be organized into hierarchical groups whose usage of various types of resources can then be limited and monitored.
In Short:
* Control Groups = Limits how much you can use or grouping object and setting limits.
* Namespaces = Limits what you can see or it is about isolation
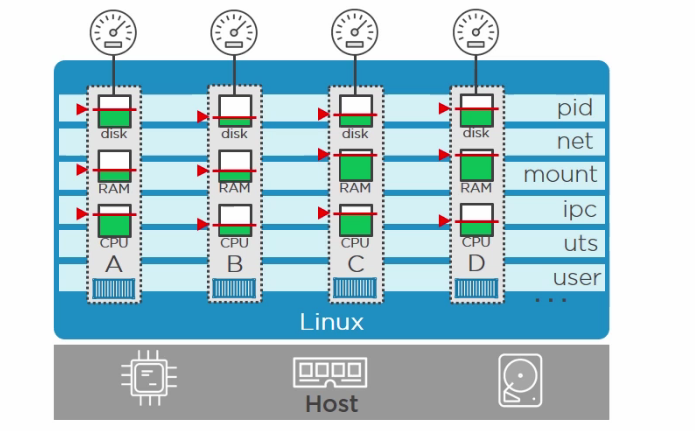
In image above, we have 4 containers, which are isolated from each other using namespaces. And these isolated containers have limited resources applied to them using control Groups. I know it seems easy because Docker has made it easy via its Docker Engine.
Note: Namespaces and Control groups are two building blocks for building containers.
Lets talk about it in detail: Namespaces are like hypervisor technology, see below image and if you notice then hypervisor creates multiple virtuals machines which act exactly like a computer having its own hardware as it shares the base system hardware resources and on other hand Namespaces provide us with virtual OS in containers where each container is exactly like a regular OS and all the container are isolated.
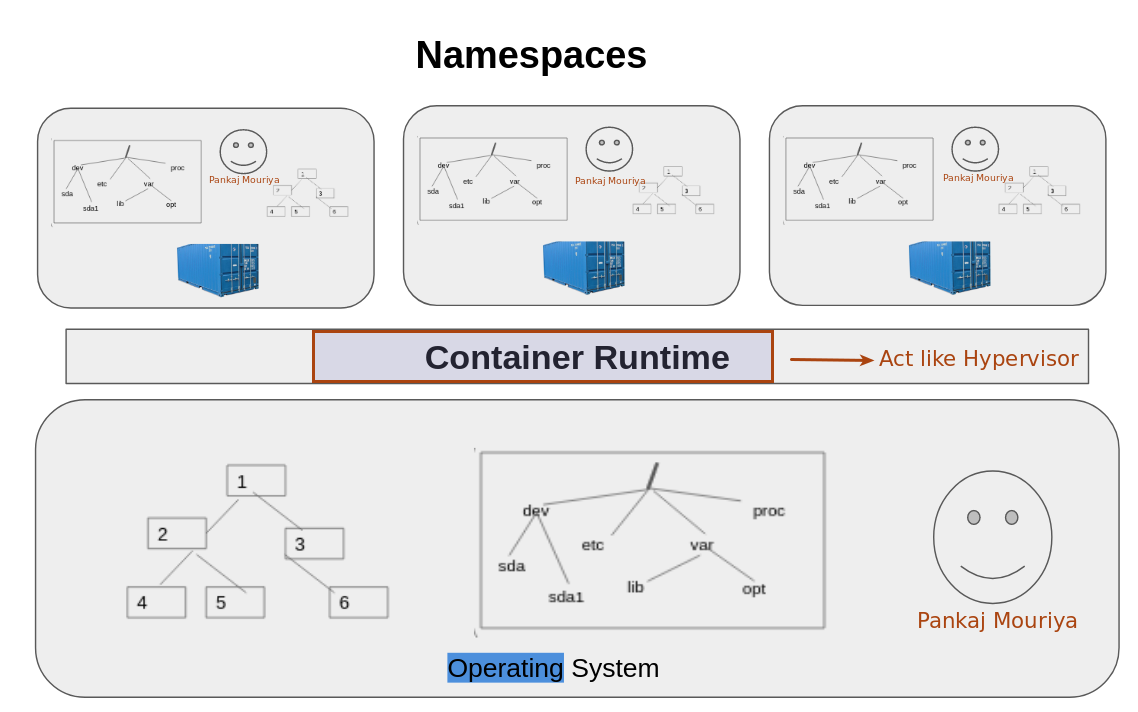
Animated slide for better understanding Click here
In Linux we have the following Namespaces.
Namespace Constant Isolates
* Cgroup CLONE_NEWCGROUP Cgroup root directory
* IPC CLONE_NEWIPC System V IPC, POSIX message queues
* Network(net) CLONE_NEWNET Network devices, stacks, ports, etc.
* Mount(mnt) CLONE_NEWNS Mount points
* PID CLONE_NEWPID Process IDs
* User(user) CLONE_NEWUSER User and group IDs
* UTS (uts) CLONE_NEWUTS Hostname and NIS domain name
and see below images to understand how this namespaces are allocated when containers are created
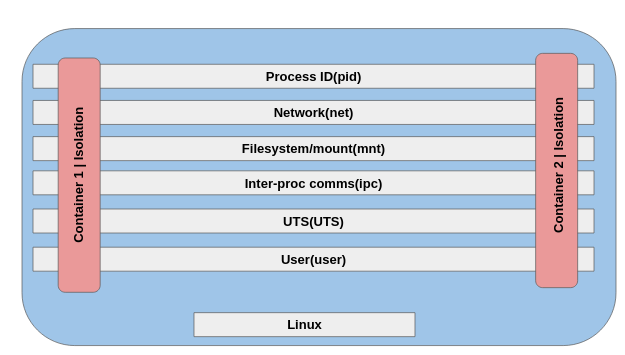
So container 1 here has its own process ID table with PID,
- own network namespace, IP address and
- own file system.
And as Namespaces are known for isolation so each container has its own secure boundary. Container 1 can not know that there is another container also running on the base machine.
PID : It gives itw own isolated process tree, complete with its own PID one.
Network(net) : Each container is given its own isolated network stack
Mount: It gives a container its own root file system.
So on linux we will have /
IPC : It lets processes in a single container access same shared memory.
UTS: It gives every container its own hostname
User : User namespace lets user map accounts inside the container to different users on host.
Now we know what is namespace, lets talk about use of control groups
Look into image below and assume that container 4 is used for some heavy work and is using all the system memory, then It might make other conatiners slow. So to control that thing we have Control Groups. Control groups assign and manage that how much memory and system resources need to be allocated to one container.
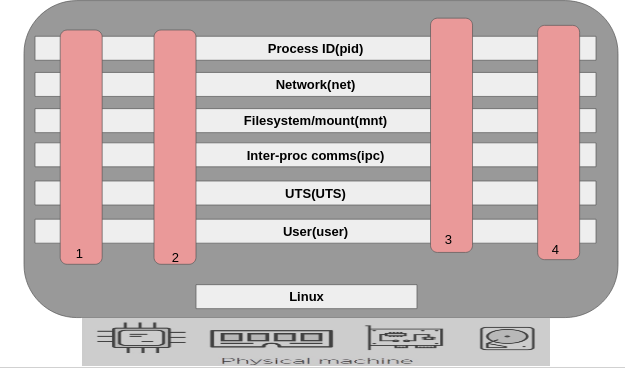
So Docker uses control groups to manage all these things, the below picture explains well.
Docker Engine
Its the Docker engine which manages everything like, generating a API request for client, handling kernel level stuff and creating containers.
At the backend Docker looks like this:
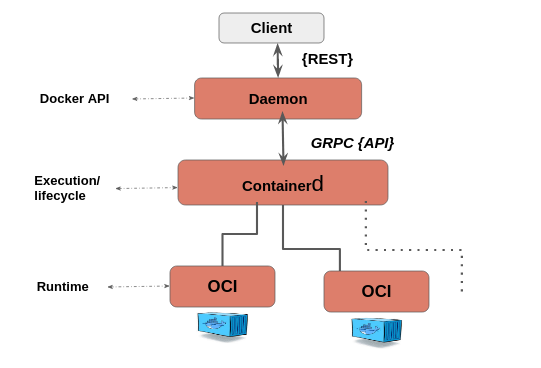
Client : Where we run commands like Docker run
/usr/bin/docker
Daemon: Also called Dockerd. It implements the rest API
/usr/bin/dockerd
ContainerD : It handles execution and lifecycle operations like start, stop, pause.
/usr/bin/docker-containerd
* Image push and pull
* Managing of storage
* Of course executing of Containers by calling runc with the right parameters to run containers...
* Managing of network primitives for interfaces
* Management of network namespaces containers to join existing namespaces
OCI(Open Container Initiative) : Under OCI we have RunC which helps in Interfacing with the kernel for Namespaces and Control Groups
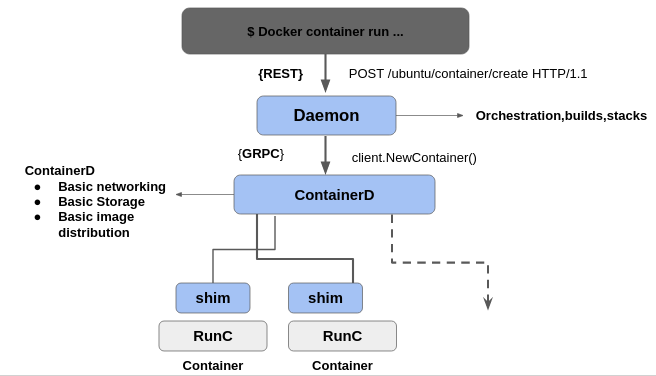
Lets relate this backend architecture while considering example of creaing a new container.
- On Docker Client when we run docker container run posts an API request to the container's endpoint in the daemon.
- But there is no logic implemented on Daemon to run container as all that sort of logic is written and implemented into ContainerD in the OCI.
Note: Containerd fully leverages the OCI runtime specification1, image format specifications and OCI reference implementation (runc). Because of its massive adoption, containerd is the industry standard for implementing OCI
- So the daemon calls out to Container D over a GRPC API on a local Unix socket, still ContainerD will not be able to create container and run it, because all the kernel level interfacing is implemented by the OCI.
- All the Logic to interface with the Namespaces and stuff in the kernel is implemented by th OCI.
- So ContainerD starts a shim process for every container and RunC creates the container and then immediatly RunC exits. So RunC is called for every new container but it will exit again and again.
- RunC exits so that we don't have long running runtime process for containers. Shim also allows the container's exit status to be reported back to a higher level like Docker
For more understanding, follow image below with above points
Animated slide for better understanding Click here